Research Engineer · Model Efficiency & On-Device ML
I make modelsefficient enoughto run onbare silicon
Model optimization, on-device inference and algorithmic efficiency across the full ML stack — squeezing every token out of any accelerator, from a Transformer synthesized to silicon to LLMs finetuned and deployed at scale.
// model efficiency · on-device ML · every token, any accelerator
// summary
As brute-force scaling hits diminishing returns, the next leap in AI comes from efficiency and adaptation — squeezing every token out of any accelerator, and that's where I work.
Research engineer with 10+ years and a Ph.D. in Engineering (Explainable AI), focused on efficient intelligence: model optimization, on-device inference and algorithmic efficiency across the full ML stack. I distill, quantize, prune and reparameterize models to ~1 ms for CLIP/SAM on Apple Silicon, and finetune and deploy LLMs at scale on Nvidia GPUs. Co-design spans algorithms, software and hardware — from FPGA designs like gateGPT (a full Transformer synthesized to RTL at ~56k tokens/s) to PyTorch optimization.
- PhD in Engineering · AIUPB · 2017–2022 · Cum Laude
- Senior AI / ML EngineerAI Startup (stealth) · Remote · since 2024
- Professor & researcherUPB · since 2009
- 10+ yearsacross research & industry
// experience
- Oct 2024 — PresentMiami, US · Remote
Senior AI / ML Engineer
AI Startup (stealth)
I squeeze CLIP/SAM-class models to ~1 ms on the Apple Silicon Neural Engine — distilling, quantizing and reparameterizing them to adapt offline, in real time — and build the backend behind Generative UI on iOS. Optimization runs end to end, across algorithms, software and hardware.
- Jan 2009 — PresentMedellín, CO
Professor & Researcher · Computer Science
Universidad Pontificia Bolivariana
- Courses: Operating Systems, AI on the Edge, Machine Learning, Embedded Systems and Computer Architecture.
- Dec 2014 — Jun 2017Medellín, CO
Co-founder & Embedded Systems Engineer
GREEMSY
- DSP acceleration platforms for software-defined radio using Nvidia Jetson embedded architecture.
- Libraries for the 16-core Epiphany coprocessor (Parallella) for ultra-low-power software-defined radio.
- LTE schedulers on a hybrid FPGA + embedded-GPU architecture.
On-device AI · stealth startup
Real-time intelligence, running fully on-device.
Selected demos from a stealth AI startup — CLIP/SAM-class models distilled and quantized to ~1 ms on Apple Silicon, adapting offline with no cloud. Plus backend engineering working hand in hand with Generative UI, shipped directly on iOS.
// selected projects
- 012026Hardware · Transformer → RTL
gateGPT — Transformer to silicon
56,000+ tokens/sec at just 80 MHz — no GPU, no CPU. I burned a full Transformer (RMSNorm, multi-head causal attention, MLP, persistent KV cache) into custom digital silicon — designed gate by gate as a 100% digital IC and prototyped on a Xilinx Virtex-5 FPGA. Algorithm, Q5.11 fixed-point, microcode ISA and datapath co-designed as one system: 28× throughput, bit-exact to a Python reference — pure silicon running Karpathy's microGPT, spelling out names on a tiny LCD.
Repository ↗ - 02
 2024iOS app · Core ML
2024iOS app · Core MLCLIP Finder
Offline semantic photo search by natural language or camera. CLIP model optimized for the Apple Neural Engine + MPSGraph (pre/post on GPU).
Image search in the photo gallery using live camera video or natural-language text as input. Every search runs offline, with computation happening mostly on the iPhone's Apple Neural Engine. Prediction times: 1.42 ms for the CLIP-Image model and 1.27 ms for the CLIP-Text model.
Repository ↗ - 03
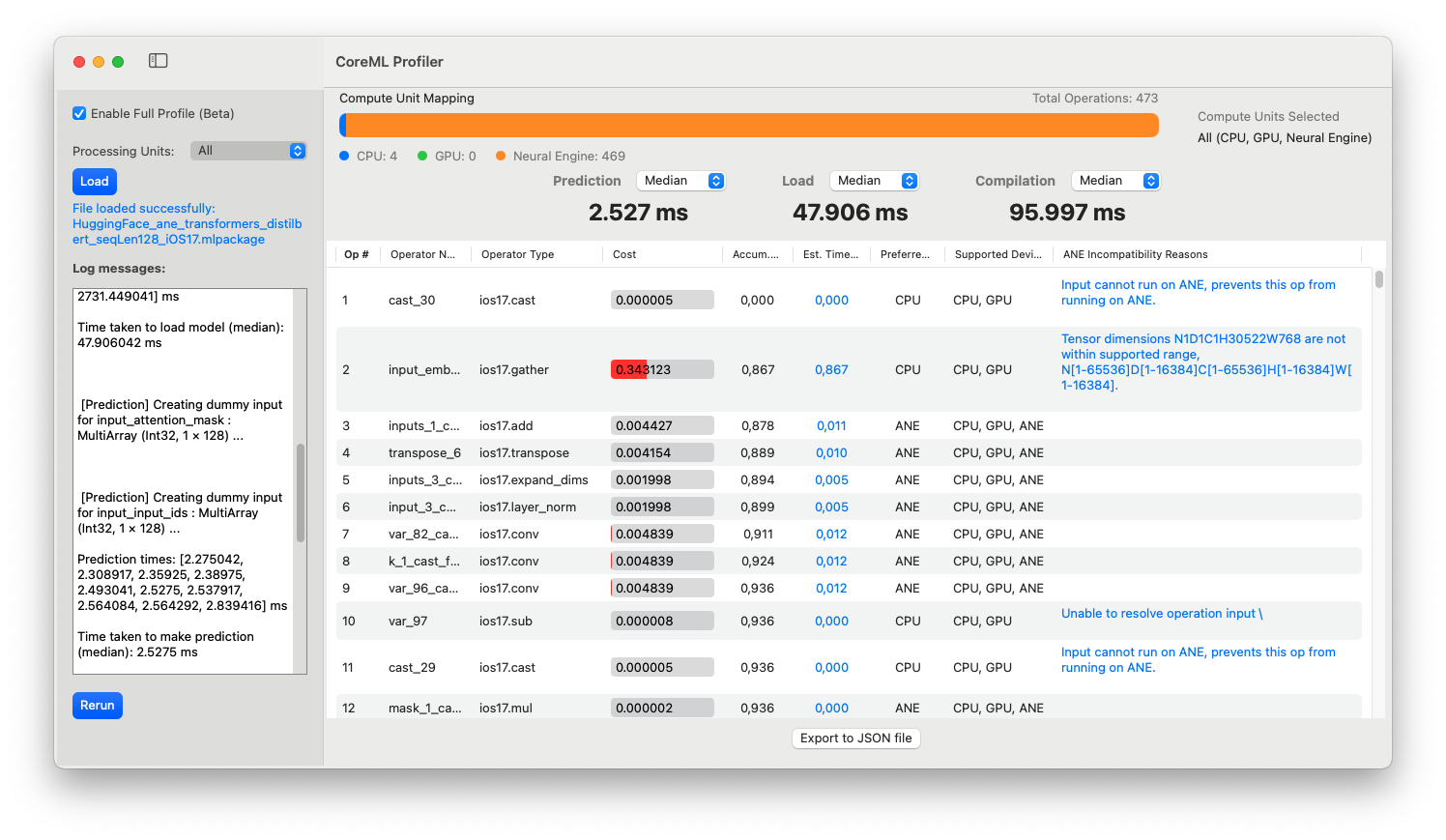
 2024macOS tool
2024macOS toolCore ML Profiler
Detailed instrumentation tool for the Apple Neural Engine: profiles Core ML models layer by layer, surfacing estimated execution times and the exact reasons each layer is or isn't compatible with the Apple Silicon accelerator.
Repository ↗ - 04
 2017–2022Research · PhD
2017–2022Research · PhDExplainable AI — PhD Thesis
Attribution methodologies to identify concepts in CNNs and produce reliable explanations: confidence, transparency and security. Cum Laude.
Repository ↗ - 05
 2005Hardware · RISC
2005Hardware · RISCNatalius RISC
Designed and simulated a RISC processor suitable for tape-out in SKY 130nm technology, with a hand-coded assembler-level compiler.
OpenCores ↗ - 06
 2023LLMs · Education
2023LLMs · EducationLLM deployment & finetuning
Locally fine-tuned LLMs over an engineering question bank to generate exams; inference with llama.cpp on Nvidia GPUs, optimized for throughput and memory footprint.
- 07
 2021Research
2021ResearchAdversarial samples mitigation
Concept retrieval in CNNs using reliable explanations to mitigate errors induced by adversarial samples.
- 08
 2023Research · Health
2023Research · HealthEarly detection of developmental disorders
Advising on projects applying LLMs for the early identification of developmental disorders in infants through babbling analysis.
// skills
Languages
- Python
- JavaScript
- TypeScript
- Swift
- SwiftUI
- C
- C++
- Verilog
Model Optimization & Efficiency
- Distillation
- Quantization
- Pruning
- Reparameterization
- Finetuning
- RLHF
- Cross-tokenizer distillation
- On-device / Neural Engine inference
- llama.cpp
ML & Deep Learning
- PyTorch
- JAX
- Core ML
- MPSGraph
- Unsloth
- TorchTune
AI Agents & LLMs
- MCP servers
- Vercel AI SDK
- Tool schema design
- Prompt engineering
- Evaluation harnesses
Cloud & Infrastructure
- AWS
- Docker
- CI/CD pipelines
- Observability (logs · metrics · tracing)
Backend & Frameworks
- Node.js
- Next.js
- Restify
- Fastify
Tools
- Xcode
- VS Code
- Git
- Linux shell scripting
// education
- 2017–2022
PhD in Engineering · Artificial Intelligence
Universidad Pontificia Bolivariana · Medellín · Cum Laude
Explainable AI: Methodologies for Identification and Retrieval of Concepts Applied to Convolutional Neural Networks.
- 2012–2013
Master of Advanced Studies · Embedded System Design
Università della Svizzera italiana (USI) · Lugano, Switzerland · with ETH & Politecnico di Milano
Wireless Communications with FPGA.
- 2009–2011
M.Sc. in Engineering · Telecommunications
Universidad Pontificia Bolivariana · Medellín
Symbol timing and carrier phase synchronization in digital receivers.
- 1999–2005
B.Sc. in Electronics Engineering
Universidad Pontificia Bolivariana · Medellín
32-bit RISC Processor.
// awards & certifications
Fellowship awards
- Minciencias, ColombiaFull PhD scholarship & research grant · 2017–2022
- ALaRI · USI LuganoFull scholarship · MAS Embedded Systems · 2012–2013
Licenses & certifications
- Deep Learning Specialization (5 courses)Coursera · Oct 2018
- Building Transformer-Based NLP ApplicationsNvidia · Jun 2022
- Fundamentals of Accelerated Data Science with RAPIDSNvidia · Jun 2022
// how i think
